행정안전부_일반음식점 데이터를 기준으로 데이터 정리를 해보았다.
먼저 판다스를 이용하여 파일을 로드했다
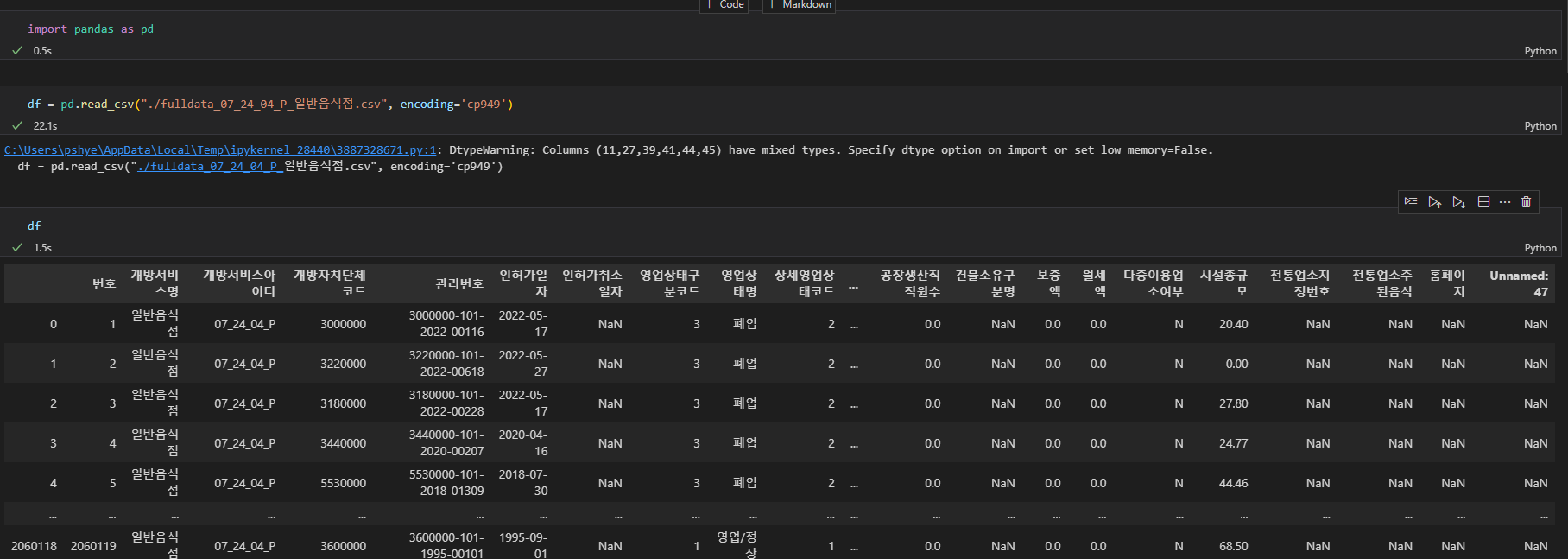
정부 관련 파일들은 대부분 인코딩 형식이 cp949이다.
encoding='cp949'를 추가한다.
df = pd.read_csv("./fulldata_07_24_04_P_일반음식점.csv", encoding='cp949')
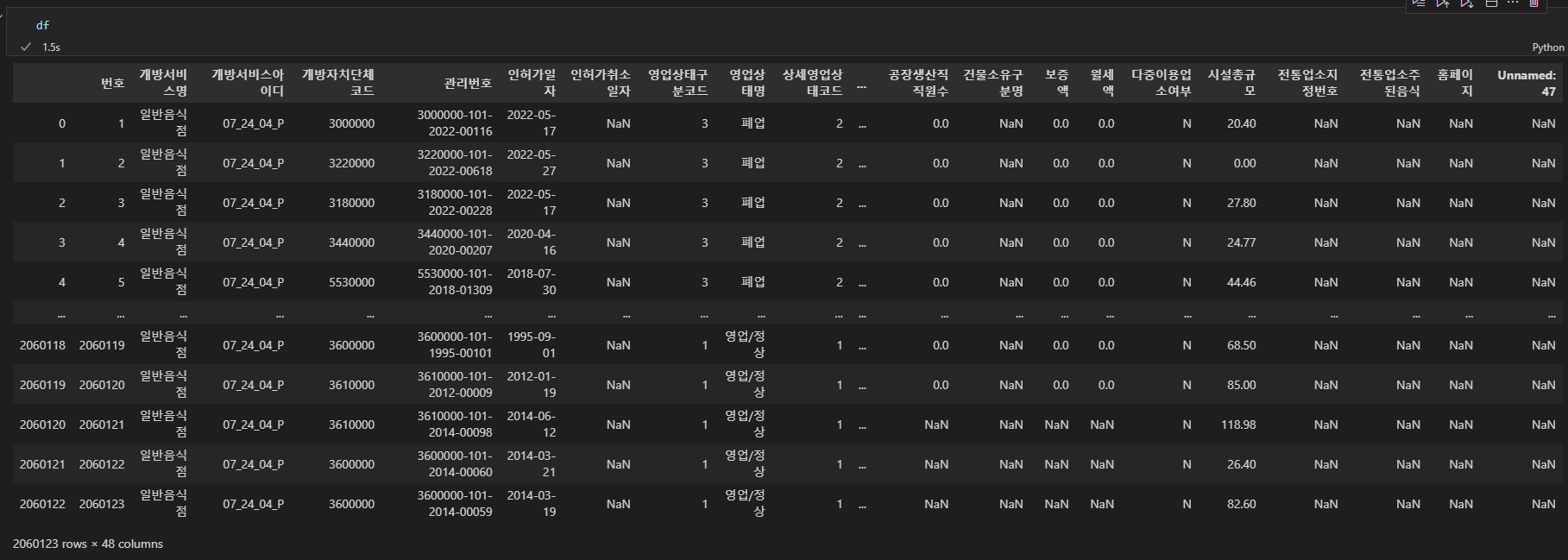
데이터 프레임은 206만 123개의 row가 있다.
전국 음식관련 업종이 206만여개가 있다는 뜻이다.
하지만 영업상태명을 보았을때 폐업이 있는 것으로 보아 현재 영업중인 파일만 출력하기로 한다.
# 폐업구분
df = df.query("영업상태명!='폐업'")
영업상태명컬럼에서 폐업이 아닌 데이터만 남긴다.
2,060,123 rows -> 691,795 rows 약 1/3의 데이터 드롭
# 컬럼 정리
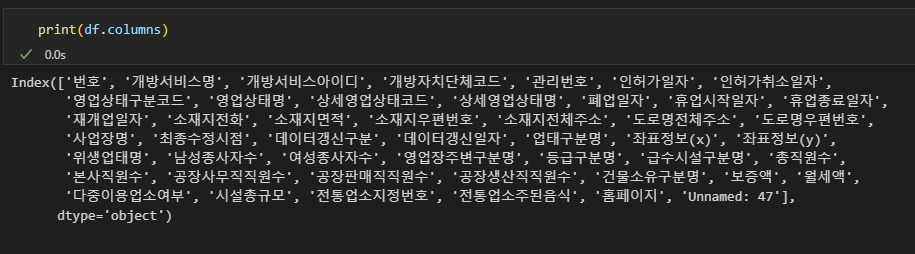
불러온 데이터 프레임의 컬럼을 본다면 실제로 결측치인 경우가 많다.
필요 없는 데이터와 함께 계속 데이터 프레임을 확인하며 데이터 프레임을 드롭한다.
df = df.drop(['인허가일자', '인허가취소일자', '영업상태구분코드','시설총규모','소재지전화'], axis=1)
df = df.drop(['위생업태명', '남성종사자수', '여성종사자수', '영업장주변구분명',
'등급구분명', '급수시설구분명', '총직원수', '본사직원수', '공장사무직직원수', '공장판매직직원수', '공장생산직직원수',
'건물소유구분명',], axis=1)
df = df.drop(['홈페이지','Unnamed: 47','개방서비스아이디', '폐업일자', '휴업시작일자', '휴업종료일자', '재개업일자'], axis=1)
df = df.drop(['소재지면적', '소재지우편번호','데이터갱신구분','개방서비스명','관리번호', '상세영업상태코드', '도로명우편번
호'], axis=1)
df = df.drop(['번호','상세영업상태명','영업상태명'], axis=1)

# 지자체 기준으로 정렬
해당 데이터는 개방자치단체코드라는 컬럼으로 각 지자체 라벨링이 되어있다.
df_label = df['개방자치단체코드'].unique()


len 을 이용하여 df_label의 개수를 확인하여보면 229개로 나온다.
기초지자체의 개수를 확인하여 보니 229개가 맞다.

# 데이터 재정렬

기초지자체를 기준으로 파일을 따로 관리하고자 한다.
따라서 쉽게 정리하기 위해 개방자치단체코드를 기준으로 재정렬한다.
df_sorted = df.sort_values(by='개방자치단체코드')
# csv파일로 출력
from tqdm import tqdm
dfs = []
for code in df['개방자치단체코드'].unique():
temp = df_sorted[df_sorted['개방자치단체코드'] == code]
dfs.append(temp)
# 생성된 데이터프레임 출력하기
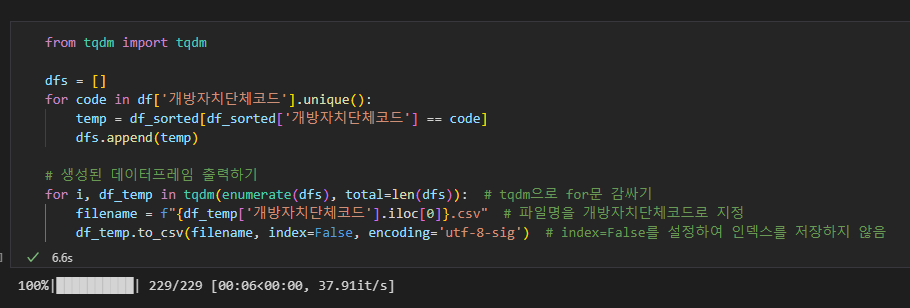
for i, df_temp in tqdm(enumerate(dfs), total=len(dfs)):
filename = f"{df_temp['개방자치단체코드'].iloc[0]}.csv" # 파일명을 개방자치단체코드로 지정
df_temp.to_csv(filename, index=False) # 인덱스를 저장하지 않음
먼저 변환 과정이 얼마나 시간이 걸리는지를 확인하기 위하여 tqdm모듈을 임포트 하였다.
dfs 라는 빈 리스트를 만들고. 229개의 개방자치단체 코드와 일치하면 정렬된 파일을 리스트에 추가한다.
df_sorted['개방자치단체코드'] == code
일때 temp에 해당 컬럼들을 temp로 정의해놓고
dfs 리스트에 추가한다.
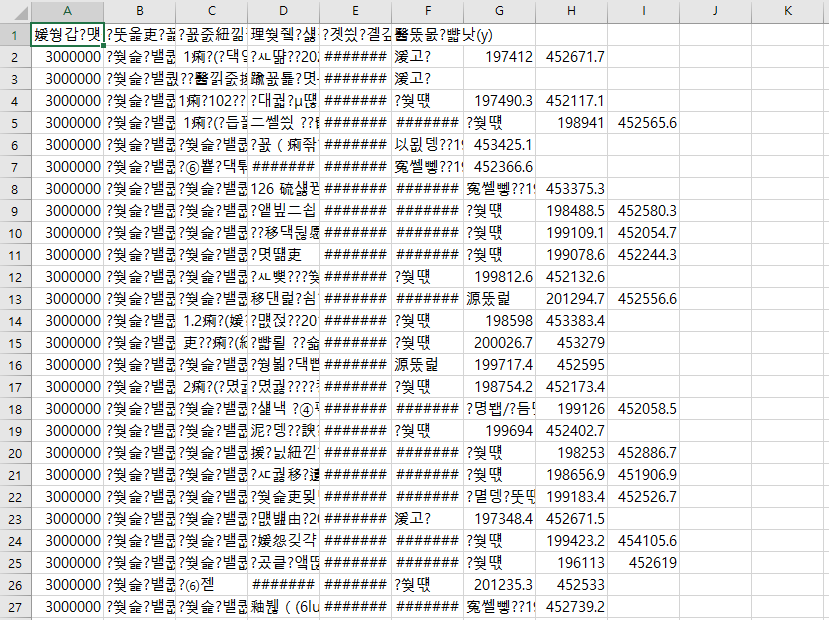
csv 파일로 저장한 결과 글자가 다 깨졌다.
# 인코딩 형식 지정
정부 csv 파일은 대부분 cp949 이다.
인코딩형식을 지정하지 않아서 발생하는 것으로 utf-8-sig로 설정하면 위와 같은 문제를 해결 할 수 있다.